

How to alert on high cardinality data with Grafana Loki
Amnon is a Software Engineer at ScyllaDB. Amnon has 15 years of experience in software development of large-scale systems. Previously he worked at Convergin, which was acquired by Oracle. Amnon holds a BA and MSc in Computer Science from the Technion-Machon Technologi Le’ Israel and an MBA from Tel Aviv University.
Many products that report internal metrics live in the gap between reporting too little and reporting too much. This is the everlasting dance between having just enough information to identify an issue, while not overloading your metrics collection server.
But what do you do when too much is not enough?
For this article, I’ll use the example I’m most familiar with, Scylla Monitoring Stack, which uses Prometheus for metrics collection. Yet this should apply to any system currently built on Prometheus and now considering Loki.
In this blog post I will cover the following:
- The cardinality problem in general and why it’s even harder with Scylla
- How using Loki 2.0 helped us overcome that
- Combining logs and metrics
Introduction
Cardinality in the context of databases in general and metrics collection specifically is the number of distinct values — to make it simple, how many different metrics are there?
It’s important to note that with metrics collection servers like Prometheus, labels are in fact part of the metric definition. So the same metric name, with two label values: two metrics.
What’s the problem with high cardinality? (A fancy way to say we’ve got lots of metrics.)
Metrics collection servers are highly optimized to store time series. For example, the case of time series that reports the same value will take almost no disk space.
So one metric that has a million values is a few orders of magnitude less expensive than a million metrics each with a single value.
Scylla and the cardinality problem
Scylla is a distributed database that uses a shard-per-core architecture. Each CPU core acts and is monitored as a separated execution unit.
If you have a 100-node cluster with 128 cores each, for every metric that is defined within Scylla, 12,800 metrics would hit your Prometheus server.
For global metrics, it works, but Scylla is a database, so what if we want to monitor all tables? Or get a Prometheus alert with the relevant keys?
That would easily cross the millions of metrics line and simply would not work with Prometheus.
The example I will use for the rest of the blog post is large-cell. For best performance, having a single huge cell (out of millions) is a data-model problem that we want to inform the user about.
Using only Prometheus and Grafana, the best we could do is add a metric that such a cell was found, generate an alert when that counter increases, and send users to look for it on their own.
Loki 2.0
Last October, Loki 2.0 was released with an alternative solution to that problem. Grafana Loki is a log aggregation system inspired by Prometheus. Originally it could be used as a metric generation for Prometheus. This by itself is nice for adding ad-hoc metrics based on log messages, and something you should be familiar with.
Among the many new features of the 2.0 release is the ability to generate alerts.
This is huge. Under certain conditions, it is the equivalent of infinite cardinality.
Remember the large-cell warning? Scylla can print a warning to the log; that log-line would contain the keyspace, table name, and key; and all that information would appear in the user dashboard.
Just to compare, to achieve the same with just Prometheus, you would need a metric per key, stored as a label, which is, of course, unbound.
Before diving into the technical details of how we set it up with Scylla, note Loki’s documentation about cardinality.
In general, keep your cardinality low; Loki generates labels for you on the fly! When working with Loki, you use its query language that resembles Prometheus PromQL. When looking for a specific log line, you use labels, but instead of creating them in advance, it’s better to have fewer labels for the general search and let Loki quickly search over all the matches.
Loki and Scylla integration
I already covered the Scylla and Loki integration in this blog post.
In general:
Logs are generated and sent by rsyslog. It’s important to note that rsyslog has a few protocols, and you should choose the RSYSLOG_SyslogProtocol23Format format.
The logs are sent to Promtail, which runs alongside Loki and feeds the log lines to it.
Loki acts as three data sources:
- It sends alerts to the alert-manager.
- It creates metrics that are used by Prometheus.
- It is a Grafana data source used with Grafana Explore.
Loki alerts are shown as part of the alert table inside the Grafana dashboard.
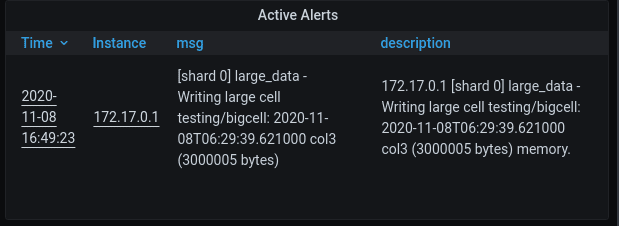
This is what an alert looks like. You can see that a user can find all the relevant details in the description.
Combining logs and metrics
As I mentioned, Loki can generate both alerts (which are sent to the Alertmanager) and metrics (which are read by Prometheus). One does not replace the other; while Loki is great at parsing a large amount of data, Prometheus is great at storing metrics.
You do need to keep in mind the cardinality issue.
Going back to our large-cell example, we will add a single metric that would count each time such a log line was identified. Notice that we have just one metric for all of our nodes and their shards, with little specific information. Adding such a metric to Prometheus adds negligible load. Now it’s easy to look at a large time frame to identify when there were such cases and then switch to Loki to know the details.
In summary: When you are monitoring for very specific (high cardinality) events that are rare, add a low cardinality metric to it to help you identify the point the event has happened.
Takeaways
We talked a lot about cardinality and looked at two products: On one side, Prometheus, the metrics collection server that excels at storing and querying multi-year time series but with a limit on cardinality. On the other side of the spectrum we have Loki (v2.0 and higher), which enables high cardinality use cases, but at the expense of limited time-range support.
Combining those tools together, where Loki generates both metrics and alerts, is a powerful capability that should be part of the toolbox of anyone that uses the Prometheus-Grafana monitoring stack.
Interested in learning more about Loki 2.0 and beyond? Don’t miss the June 17 GrafanaCONline session, “Get more and spend less with Grafana Loki for logs.” Register for free now!


