
State and health of alerts
There are three key components that help you understand how your alerts behave during their evaluation: alert instance state, alert rule state, and alert rule health. Although related, each component conveys subtly different information.
Alert instance state
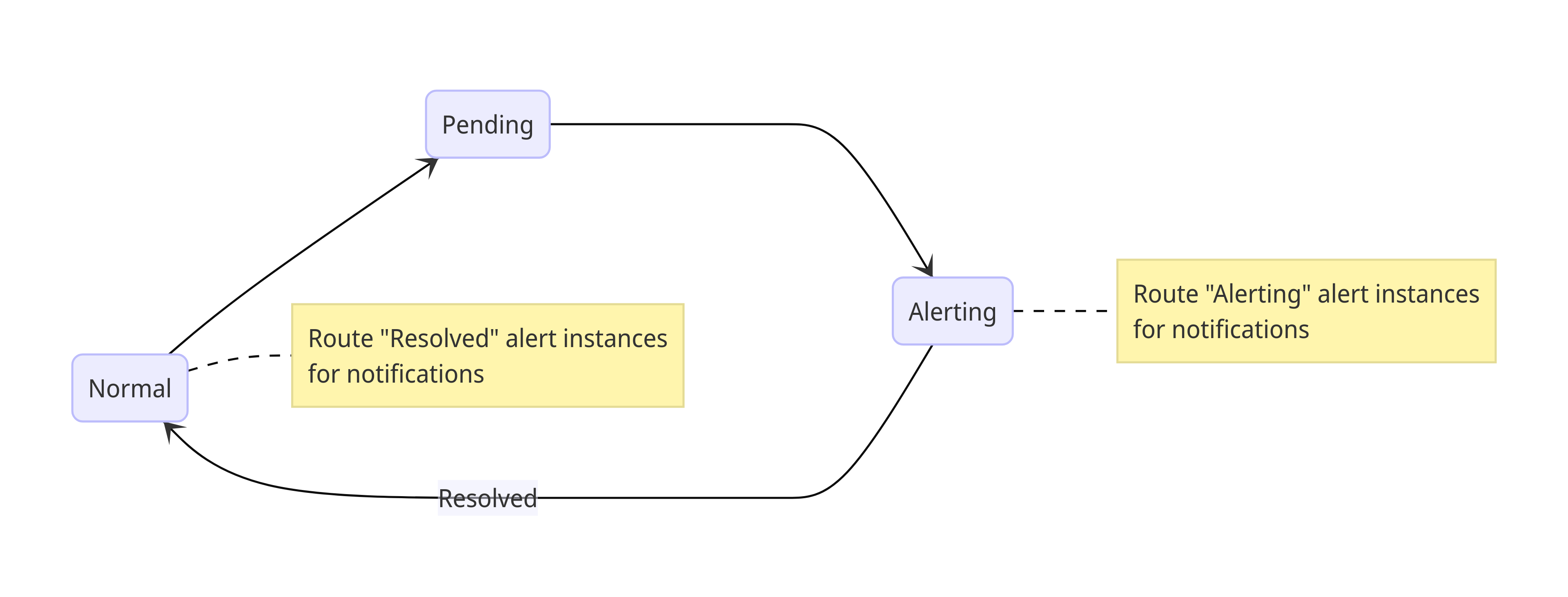
An alert instance can be in either of the following states:
| State | Description |
|---|---|
| Normal | The state of an alert when the condition (threshold) is not met. |
| Pending | The state of an alert that has breached the threshold but for less than the pending period. |
| Alerting | The state of an alert that has breached the threshold for longer than the pending period. |
| NoData | The state of an alert whose query returns no data or all values are null. You can change the default behavior. |
| Error | The state of an alert when an error or timeout occurred evaluating the alert rule. You can change the default behavior. |

Notifications
Alert instances will be routed for notifications when they are in the Alerting state or have been Resolved, transitioning from Alerting to Normal state.
Lifecycle of stale alert instances
An alert instance is considered stale if its dimension or series has disappeared from the query results entirely for two evaluation intervals.
Stale alert instances that are in the Alerting, NoData, or Error states transition to the Normal state as Resolved, and include the grafana_state_reason annotation with the value MissingSeries. They are routed for notifications like other resolved alert instances.
Keep last state
The “Keep Last State” option helps mitigate temporary data source issues, preventing alerts from unintentionally firing, resolving, and re-firing.
In Configure no data and error handling, you can decide to keep the last state of the alert instance when a NoData and/or Error state is encountered. Just like normal evaluation, the alert instance transitions from Pending to Alerting after the pending period has elapsed.
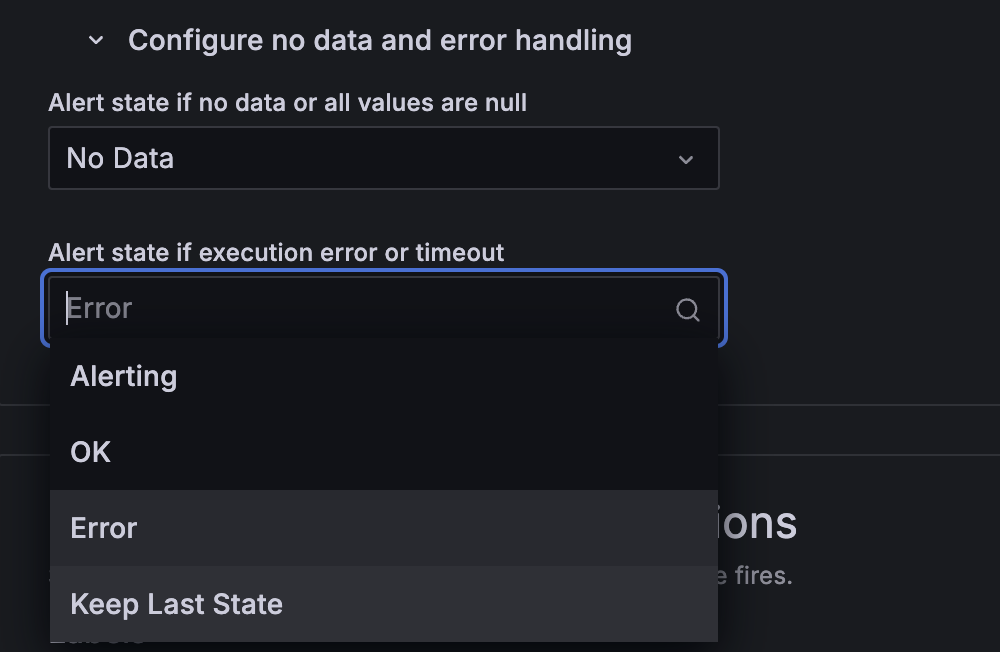
However, in situations where strict monitoring is critical, relying solely on the “Keep Last State” option may not be appropriate. Instead, consider using an alternative or implementing additional alert rules to ensure that issues with prolonged data source disruptions are detected.
Special alerts for NoData and Error
When evaluation of an alert rule produces state NoData or Error, Grafana Alerting generates a new alert instance that have the following additional labels:
alertname: EitherDatasourceNoDataorDatasourceErrordepending on the state.datasource_uid: The UID of the data source that caused the state.
You can manage these alerts like regular ones by using their labels to apply actions such as adding a silence, routing via notification policies, and more.
Alert rule state
The alert rule state is determined by the “worst case” state of the alert instances produced. For example, if one alert instance is Alerting, the alert rule state is firing.
An alert rule can be in either of the following states:
| State | Description |
|---|---|
| Normal | None of the alert instances returned by the evaluation engine is in a Pending or Alerting state. |
| Pending | At least one alert instances returned by the evaluation engine is Pending. |
| Firing | At least one alert instances returned by the evaluation engine is Alerting. |
Alert rule health
An alert rule can have one of the following health statuses:
| State | Description |
|---|---|
| Ok | No error when evaluating an alerting rule. |
| Error | An error occurred when evaluating an alerting rule. |
| NoData | The absence of data in at least one time series returned during a rule evaluation. |
| {status}, KeepLast | The rule would have received another status but was configured to keep the last state of the alert rule. |
Was this page helpful?
Related resources from Grafana Labs


